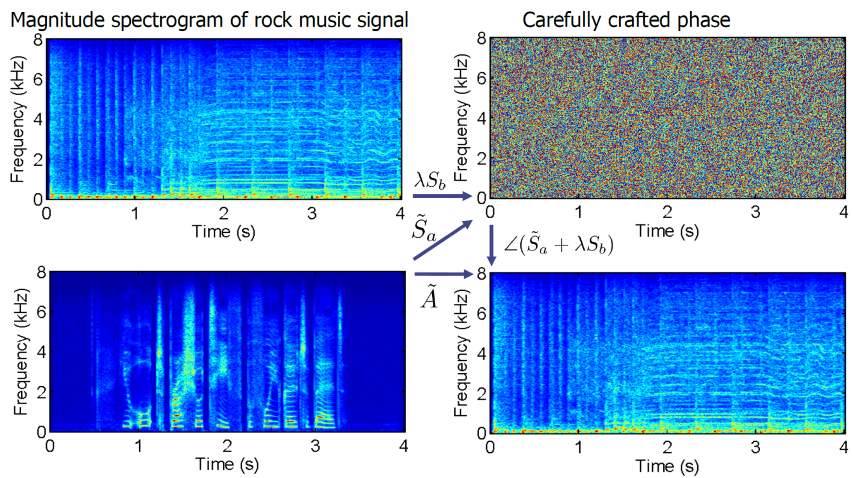
Phase-controlled sound transfer based on maximally-inconsistent spectrograms
It is generally considered that the magnitude part of an STFT spectrogram is a reliable cue to build an intuition of what a signal resynthesized from that spectrogram will sound like. Spectrogram reading and algorithms for sound reconstruction from magnitude spectrograms are striking illustrations of this idea, and one might be tempted to think that, whatever the phase combined with a given magnitude, the worse that could happen when resynthesizing a signal through inverse STFT is to obtain a noisy version of the sound that the intuition hints at. We show that it is not the case: while results meeting the intuition can indeed be obtained by minimizing what we call the "inconsistency" of a spectrogram, we investigate in this paper what happens when inconsistency is maximized instead of minimized, and explain how the same magnitude spectrogram can lead, depending on the phase it is combined with, to extremely diverse resynthesized sounds, some of them very far from what one would expect.
Reference: Jonathan Le Roux, "Phase-controlled sound transfer based on maximally-inconsistent spectrograms," in Proc. of ASJ Spring
Meeting, 1-Q-51,
Mar. 2011. [.pdf], [.bib], [Poster]
When attempting to reconstruct a signal from a target magnitude spectrogram, many methods rely on optimizing phase to minimize the inconsistency of the combined complex spectrogram.
But by optimizing phase to instead maximize inconsistency, it is possible to obtain a magnitude extremely close to the target one but for which there exists a phase such that their combination leads to silence. For this slightly modified magnitude, it is also possible to build a phase such that their combination sounds like something completely different.
For example, starting from the ever so slightly modified magnitude spectrogram of a speech signal "a" (bottom left in the figure below), one can reconstruct a rock music signal "b" (with some artefacts) by introducing information on the music signal solely in the phase. The phase can be obtained as the phase of the sum of the modified complex speech spectrogram and a scaling factor times the complex spectrogram of the music signal. Interestingly, the smaller the scaling factor, i.e., the smaller the influence of "b" in the phase, the more the reconstructed signal will sound like "b". The larger the influence of "b", the more the reconstructed signal will sound like a distorted version of the speech "a".
For more details and explanations, please refer to the poster.
Audio Samples
Speech reconstructed from (slightly) modified speech magnitude combined with original speech phase [
wav
]
Rock music reconstructed from (slightly) modified speech magnitude combined with carefully crafted phase [
wav
]